Reason
- main memory is slow
- => hierarchy of storage units keep frequently used data close to processor
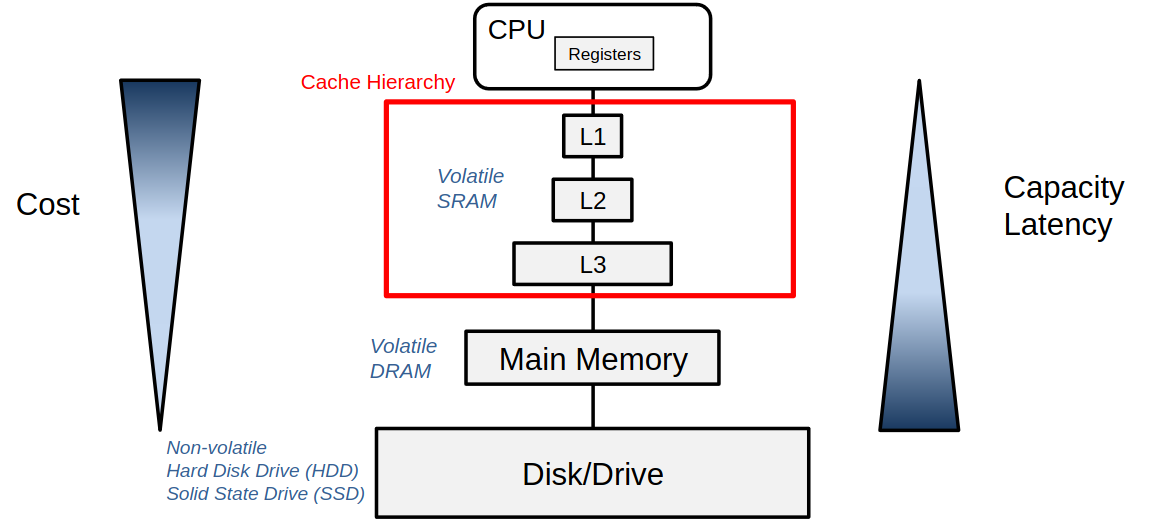
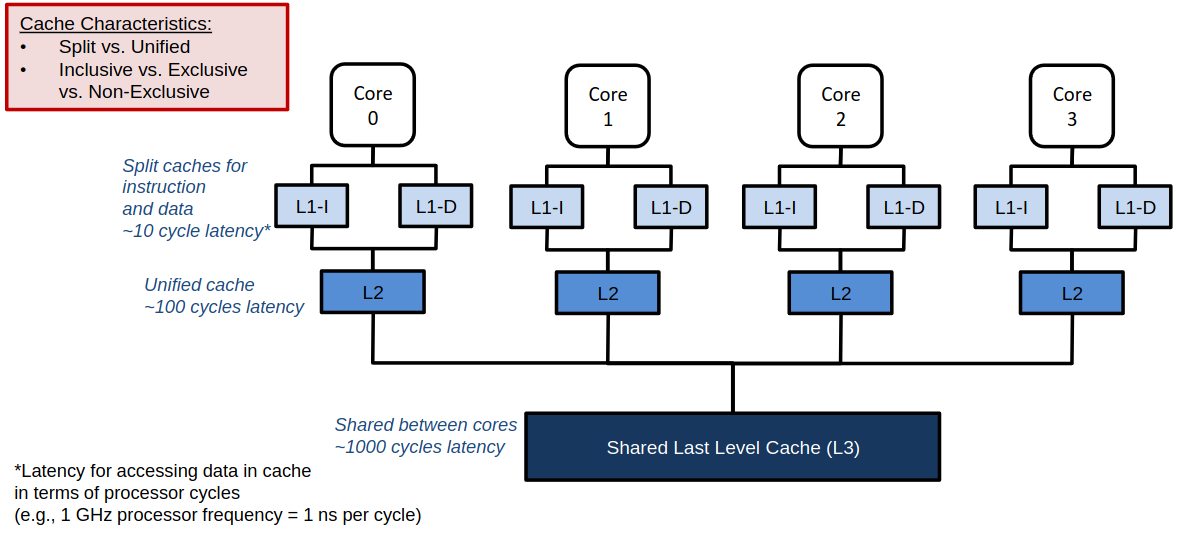
Caches
- split: ∃ separate instruction-cache & data-cache
- (+) parallel access possible#
- (+) caches can physically be closer to them accessing units
- unified: one cache for both
- inclusive: all blocks in higher level cache are also stored in lower level cache
- exlusive: all blocks in higher level cache are not stored in lower level cache
- non-exclusive: all blocks in higher level cache can be stored in lower level cache
Cache Associativity
- direct mapped: cache organized into multiple sets. One cache line per set
- set-associative: n sets wit m cache lines each
- fully associative: single cache set with m cache lines
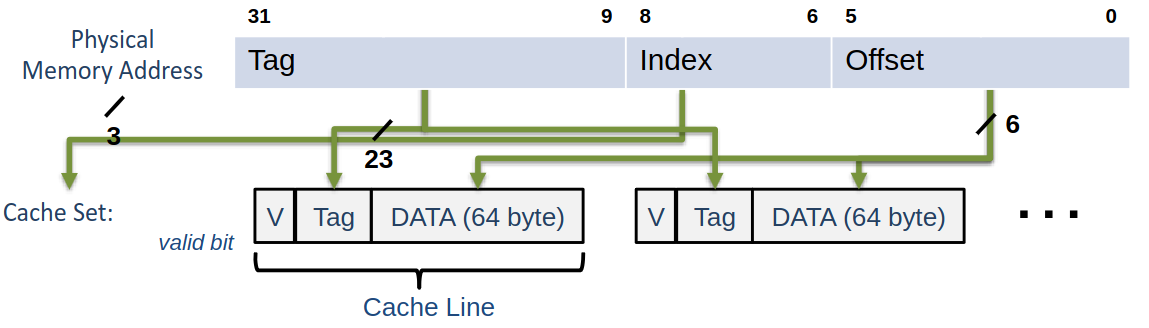
Cache Hit | Miss
- index decides set which is slelected
- compare all entries TAG with the TAG of the address
- Tag found -> Hit
- Tag not found -> Miss
Cache Addressing
- Physically Indexed Physically Tagged (PIPT): Index and Tag read out from physical memory address
- virtual to physical address translation must be done bevorehand -> slow
- Virtually Indexed Virtually Tagged (VIVT): Index and Tag read out from virtual memory address
- (+) faster
- (-) virtual address tied to one process | homonym
- (-) different virtual addresses may point to one physical address | synonym
- Virtually Indexed Physically Tagged (VIPT): Index read out from virtual memory address and Tag read out from physical memory address
- (+) address translation happens parallel to cache request
- (+) homonyms prevented
- (-) synonyms possible
Write-Hit Policies
- write back:
- write data only to cach | set dirty Bit
- uppon eviction: write data back to main memory
- write-through: write data to cach and to main memory immediately
Write-Miss Policies
- write-allocate: write miss -> load requested data into cache
- no-write-allocate: write miss -> write data directly to memory | dont allocate cache
Replacement Policies
- Least-Recently-Used (LRU): evict cache line with has not received a hit for the loongest time
- non-negligible hardware overhead to store age for every cache line
- Least-Frequently-Used (LFU): evict cache line used the least often
- Most-Recently-Used (MRU): evict cache line with has not received a hit for the shortest time
IO using IO Ports
- Access to device through special registers
- special IO instructions for reading and writing to IO ports
Memory Mapped IO
- each control register assigned a unique memory address
- no real memory assigned tho these addresses
- (+) fast access to device inputs / outputs
- (+) no need to first copy data from device registers
- (+) no extra instructions needed
- (+) protection from device IO can be performed via memory mapping
- (+) testing of device registers fast, as comparison can be done directly in memory
- (-) caching problematic | needs to be disabled for memory mapped addesses
- (-) memory addressing on systems with multiple buses complicated
Separate Memory Spaces
- data and instructin memory was split due to limited storage chips
- dedicated page tables for each memory chip
Direct Memory Access (DMA)
- DMA controller is used to perform data transfer. CPU only initializes the transfer
- saves CPU time
- DMA signals finished transfer with interrupt
- internal device buffer: required to store data while DMA waits for bus availability
- (-) in embeded systems added overhead might not be worth it
- (-) fast CPU slow DMA -> useless
DMA Operating Modes
- word-at-a-time: DMA occasionally steals bus from CPU to performe short transfers
- block- or burst-mode: series of transfers executed at once
- fly-by-mode: DMA instructs device to access memory directly (no copy)
- DAM access itself: DMA stores/reads words itself -> can performe device to device, memory to memory copies